Frequency Compression is for Speech but Not Music

Back to Basics is a monthly column written by Marshall Chasin for the Hearing Review. Permission has been granted to reprint some of these columns in Canadian Audiologist.
Frequency compression of any form can be quite useful to avoid dead regions in the cochlea for speech but this does not follow for music. The difference is that in damaged regions- typically in the higher frequencies- speech has a “continuous” spectrum, whereas music is always a “discrete” or “line” spectrum regardless of frequency. While this sounds more like an obscure lesson in acoustics, it is actually central to why frequency compression in hearing aids simply should not be used for music stimuli.
Here is the story why frequency compression can’t work with music:
A discrete spectrum, also known as a line spectrum, has energy at multiples of the fundamental frequency (f0) which is also known in music, as the tonic. If the fundamental frequency of a man’s voice (such as mine) is 125 Hz, there is energy at 125 Hz, 250 Hz, 375 Hz, 500 Hz, 625 Hz, and so on. But there is no energy at all at 130 Hz or 140 Hz- just at multiples of the 125 Hz fundamental. In speech acoustics we frequently see very pretty looking spectra for the vowel [a] or [i] (and they are pretty) but are erroneous. For the vowels and nasals of speech there is only energy at well-defined integer multiples of F0 but nothing in between those harmonics. For vowels and nasals, speech is an “all-or-nothing” spectrum- energy is there or isn’t. Speech also has higher frequency continuous spectra from the stops, affricates, and fricative phonemes.
Figure 1. All of music (except for percussion) have line spectra- distinct energy only at the harmonics and nothing in between. Speech also has line spectra for the lower frequency sonorants (vowels, nasals, and liquids). The reason why these discrete harmonics are not straight vertical lines is that the use of windows in the digitization process imparts an artefactual width.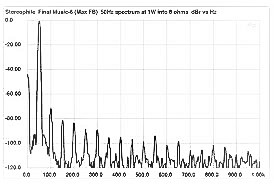
The reason why frequency compression can be so useful for speech is that speech is not only made up of discrete line spectra for voiced sonorants (i.e., vowels, nasals, and the liquids, [l] and [r]) but also higher frequency continuous spectra. The higher frequency continuous spectra are for the obstruents (stops, fricatives, and affricates) such as [s] and [š] as in ‘see’ and ‘she’ respectively. And these high frequency continuous spectra that do not rely on the well-defined properties of harmonic spacing, are usually the ones that are near cochlea dead regions. Transposing away from this region for sounds that have continuous spectra will have a minimal deleterious effect on speech intelligibility- it just moves a band of sound energy from one region to a slightly lower frequency region.
In contrast, any frequency compression for a discrete or line spectrum (such as music) would have disastrous effects- chances are great that a transposed harmonic may be within several Hz of that of an existing harmonic with a result of beats (within 20 Hz) or a fuzziness (within 30 Hz). Also, the chances of the transposed harmonic being in a different musical key, are quite high. Imagine middle C (262 Hz) having harmonics where some of them are multiples of 262 Hz, and other, higher frequency harmonics, are not at multiples of 262 Hz!
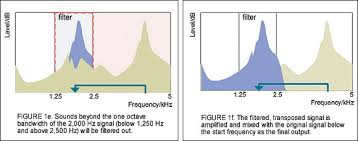
Figure 2. Sounds with continuous spectra such as the higher frequency obstruents of speech (fricatives, africates, and stops) can benefit from frequency transposition if there are dead regions in the cochlea. Music, regardless of frequency region never has a continuous spectrum. Extrapolating this to music is erroneous. Figure courtesy of www.Phonak.com.
Assuming that because frequency compression may work for nicely for speech, that it should also be useful for music, is an erroneous assumption and has nothing to do with how the brain encodes speech and music. Changing harmonic relationships for music will never improve the quality of the sound.
In cases of cochlear dead regions while listening to music, less may be more- simply reducing the gain in these damaged frequency regions, rather than shifting or transposing away would have greater clinical success.
Acknowledgment: Parts of this Back to Basics were published at http://hearinghealthmatters.org/hearthemusic/2016/frequency-compression-cant-work-for-music.